Experience
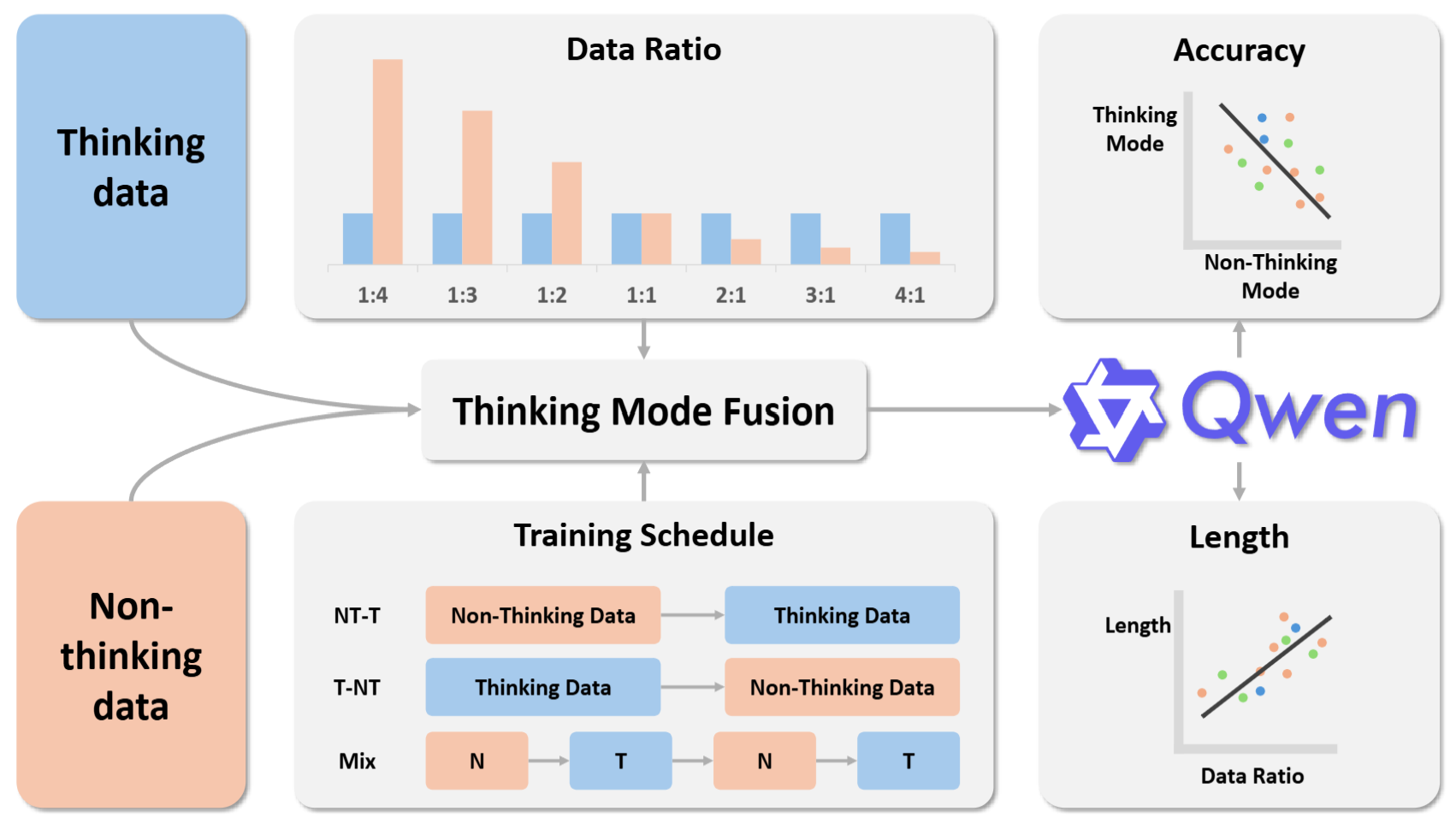
Fusion Training · Hybrid-reasoning LLMs
- Found that interleaving thinking and non-thinking training data keeps both abilities strong, and measured how the balance shifts (adding more non-thinking data steadily hurts reasoning). Released the open Fusion Bench benchmark.
- Newer LLMs mix quick answers with long step-by-step reasoning to save compute, but putting both into one model makes them fight. Ran a full grid over data ratios and training orders to see what keeps both working.
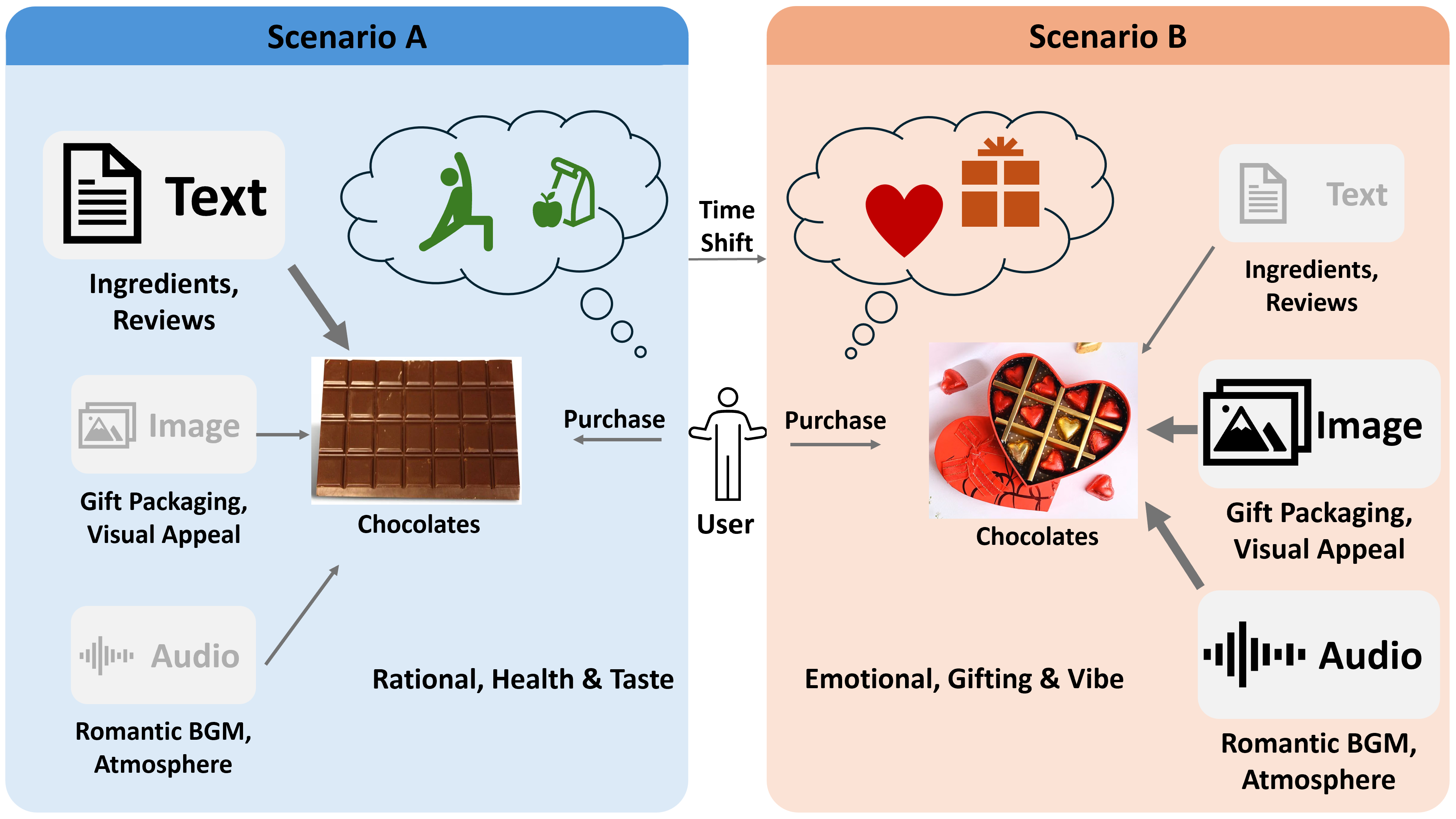
TimeRoute · Time-aware recommendation
- Raised recommendation accuracy by up to 6% on TikTok, Amazon-Baby, and Amazon-Sports over strong baselines.
- Recommenders usually mix a user’s clicks, text, and images the same way no matter when each happened. Built a model that learns which of these matter over short versus long time spans, and that cleans up noisy or missing history on its own.
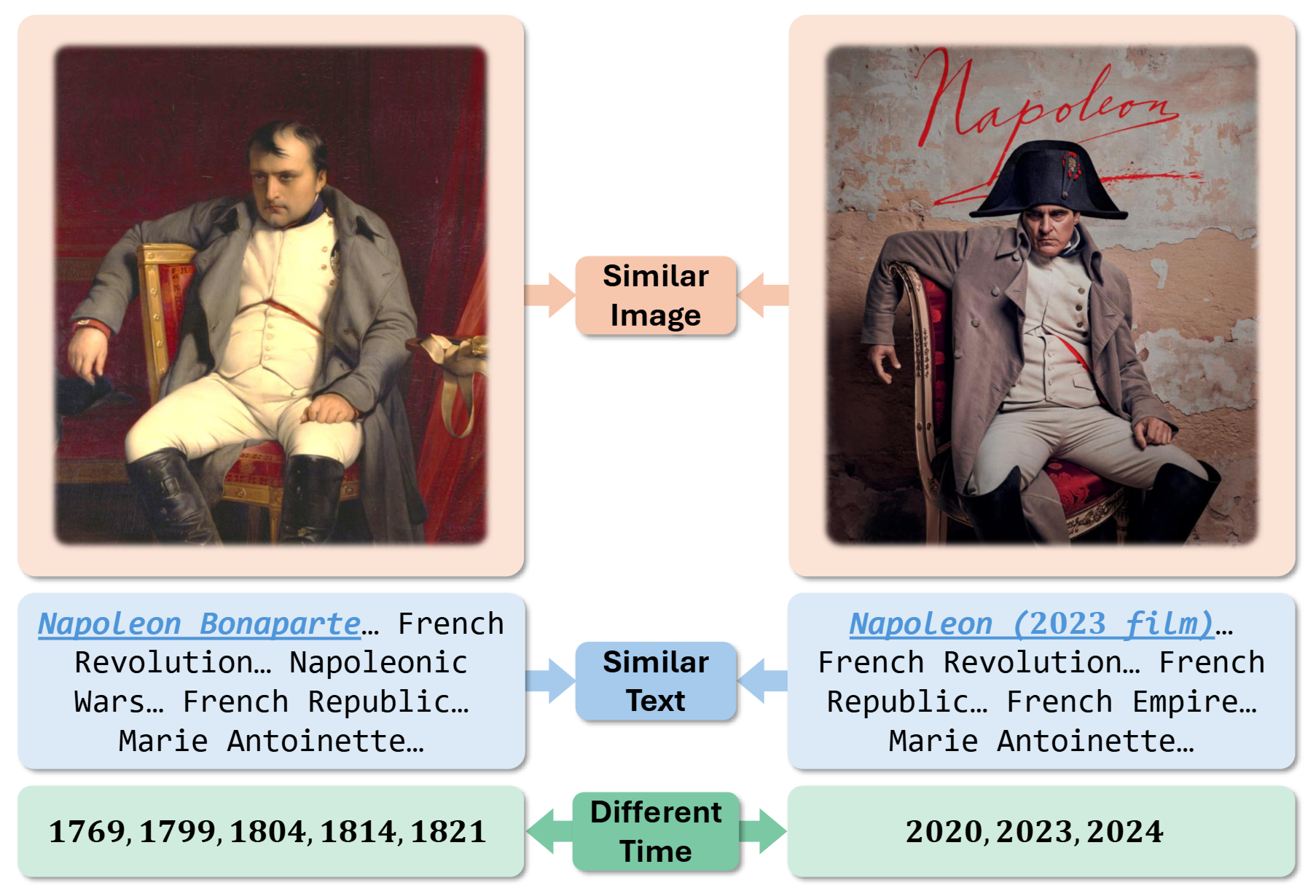
Time Imprint · Multi-modal entity disambiguation
- Raised top-match accuracy by up to 4.81% overall, and by up to 200% on the hardest, most look-alike cases.
- Systems often mix up near-identical records whose text and images look almost the same. Added time as an extra clue so the model can tell them apart, cutting errors most where they were worst.
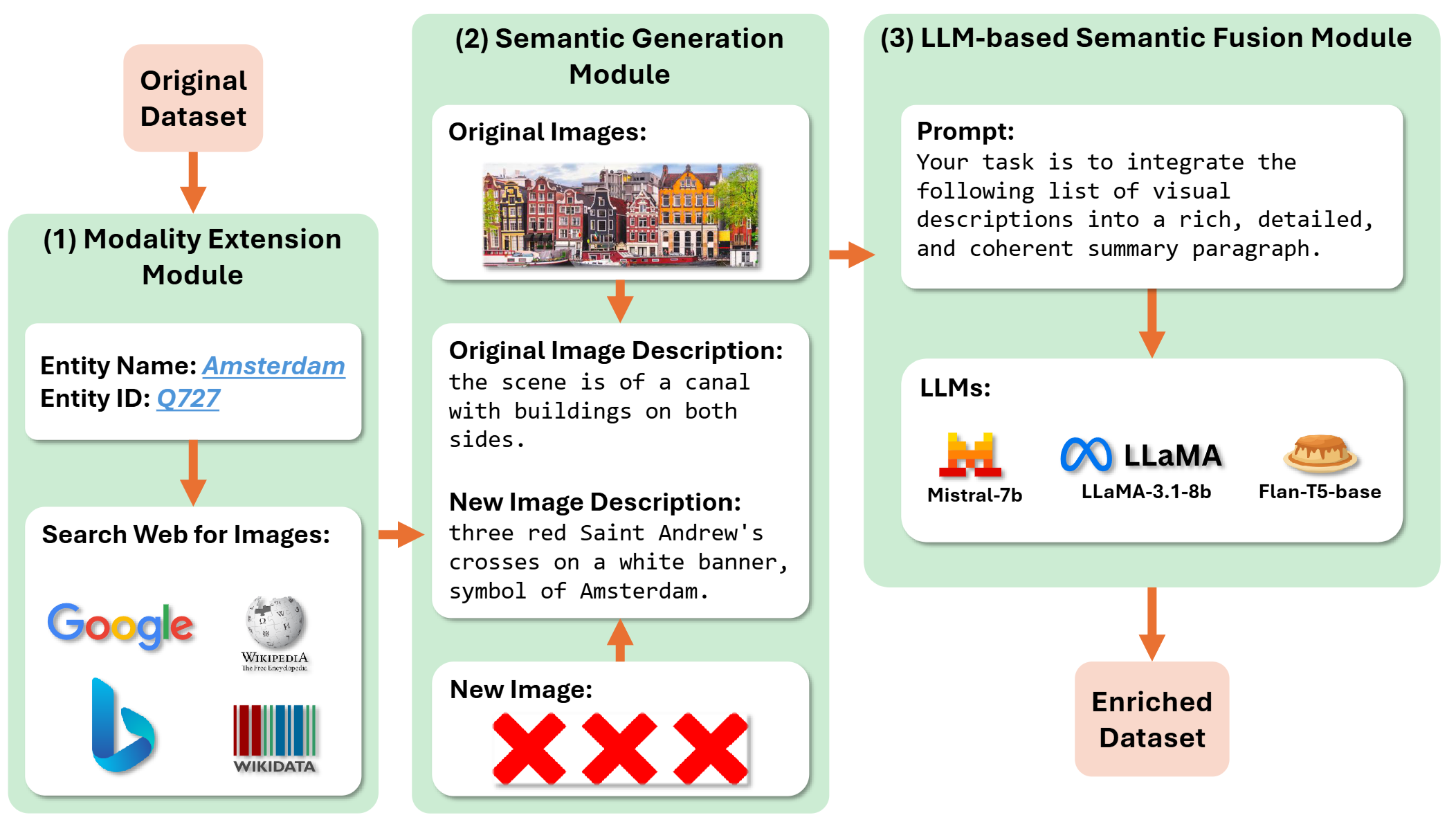
Beyond Images · Knowledge-graph data enrichment
- Raised match accuracy by up to 7% overall, and by up to 333% on ambiguous logos and symbols.
- Many records have missing or low-quality images, which hurts matching. Built a pipeline that finds extra images online, turns them into text with vision-language models, and writes a summary with an LLM, filling the gaps with no manual work.
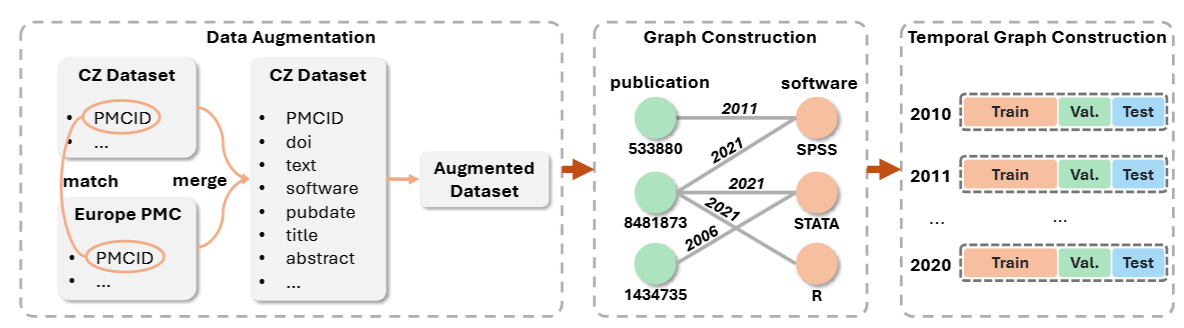
Graph-TempCZ · Large-scale graph link prediction
- Raised test accuracy by 5.98% (to 92.88%) with a GraphSAGE GNN over feature-based XGBoost baselines.
- Built the first large graph linking research papers to the software they use, with over six million mentions spanning 1959 to 2022, and checked how well the model predicts usage in later years.
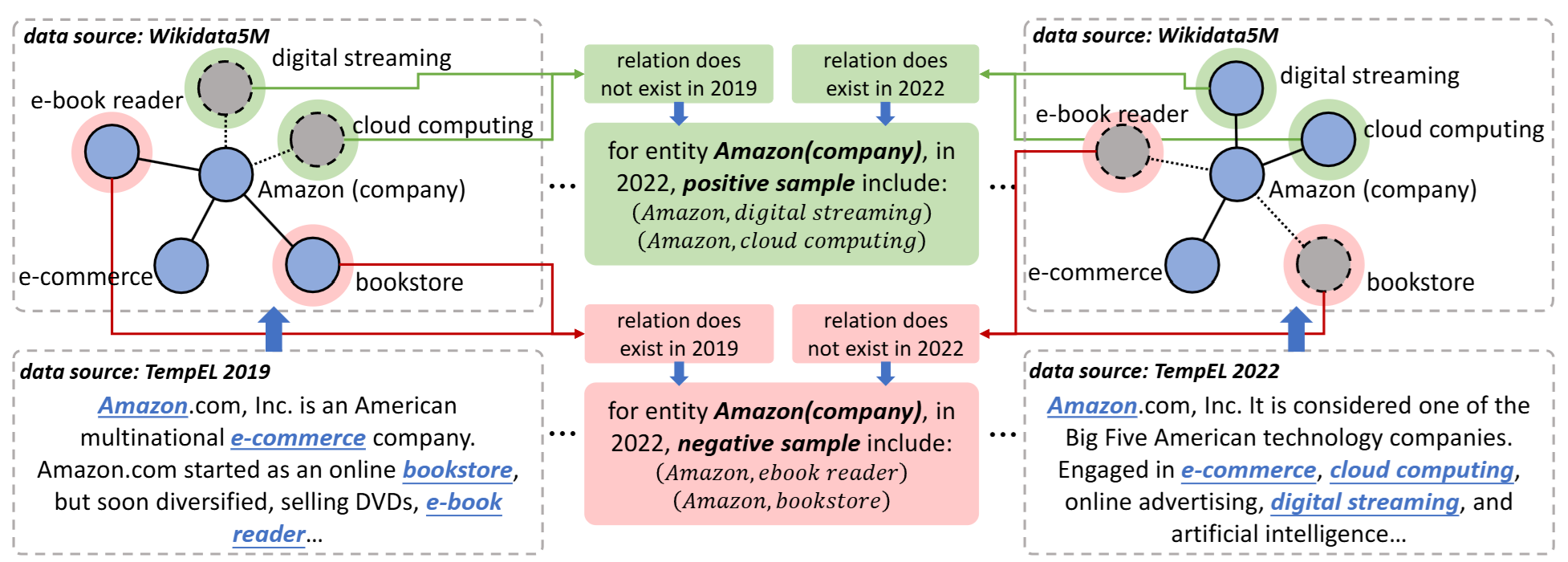
CYCLE & TIGER · Temporally robust entity linking
- CYCLE beat the best prior method by 13.9% to 17.8%; TIGER beat the strongest baseline by 16% to 21%, measured over one to three year gaps.
- Models that match text to a database lose accuracy as the database changes from year to year. CYCLE learns from those yearly changes, and TIGER also uses how records connect to each other. Both come with public benchmarks (GCL-TempEL and Graph-TempEL).
Skills
Programming
- Python
- SQL
- Bash
- Git
- Linux
Machine Learning & Deep Learning
- PyTorch
- Hugging Face
- scikit-learn
- NumPy
- Pandas
- Large language models
- Vision-language models
- Graph neural networks
- Contrastive learning
- Recommendation
Tools
- Weights & Biases
- Jupyter